【硬核体系结构与编译器技术】编译器的降维打击:从循环展开到软件流水线
概述
循环展开虽能挖掘指令级并行(ILP),但受限于寄存器溢出和指令缓存缺失,无法无限展开逼近理论极限。软件流水线通过“错位重组”迭代,以更优雅、更节省寄存器的方式逼近理论吞吐极限,但它也非银弹,受限于循环间依赖和控制流。
循环展开的理论极限与现实缺陷
1. 理论极限的量化:ResMII
ResMII(Resource Minimum Initiation Interval,资源最小启动间隔):衡量循环在特定微处理器上启动间隔上限的理论指标。
计算方法:
案例:
for (i = 1000; i > 0; i--) { x[i] = x[i] + s; }这个简单程序的循环体就是
x[i] = x[i] + s,其对应的底层汇编大概长这样(为方便理解,使用伪汇编表示):Loop: LD R1, 0(R2) ; 指令1:从内存加载 x[i] 到 R1 ADD R1, R1, s ; 指令2:算加法(R1 = R1 + s) SD R1, 0(R2) ; 指令3:把算好的 R1 写回内存 x[i] SUB R2, R2, 8 ; 指令4:指针往后退(准备处理下一个元素) BNEZ R2, Loop ; 指令5:判断是否全部处理完,没完则跳回 Loop通过拆解可以看出,该循环体包含:1 条 Load 指令、2 条算术指令(ADD 和 SUB)、1 条 Store 指令以及 1 条分支判断指令。
假设我们目标微处理器具备以下资源:4 个 ALU 单元、2 个存储器读端口(Read Port)、1 个存储器写端口(Write Port),以及 1 个分支预测单元。
根据上述信息,不难计算得到如下:
即理论上每周期可启动一次新迭代。
2. 循环展开能无限逼近 ResMII 吗?
这里需要先补充下先前循环展开的例子:
在上篇博文中,我们演示了展开 次并重新调度后的汇编代码(假设 LD 指令延迟为 4,其余指令延迟为 1):
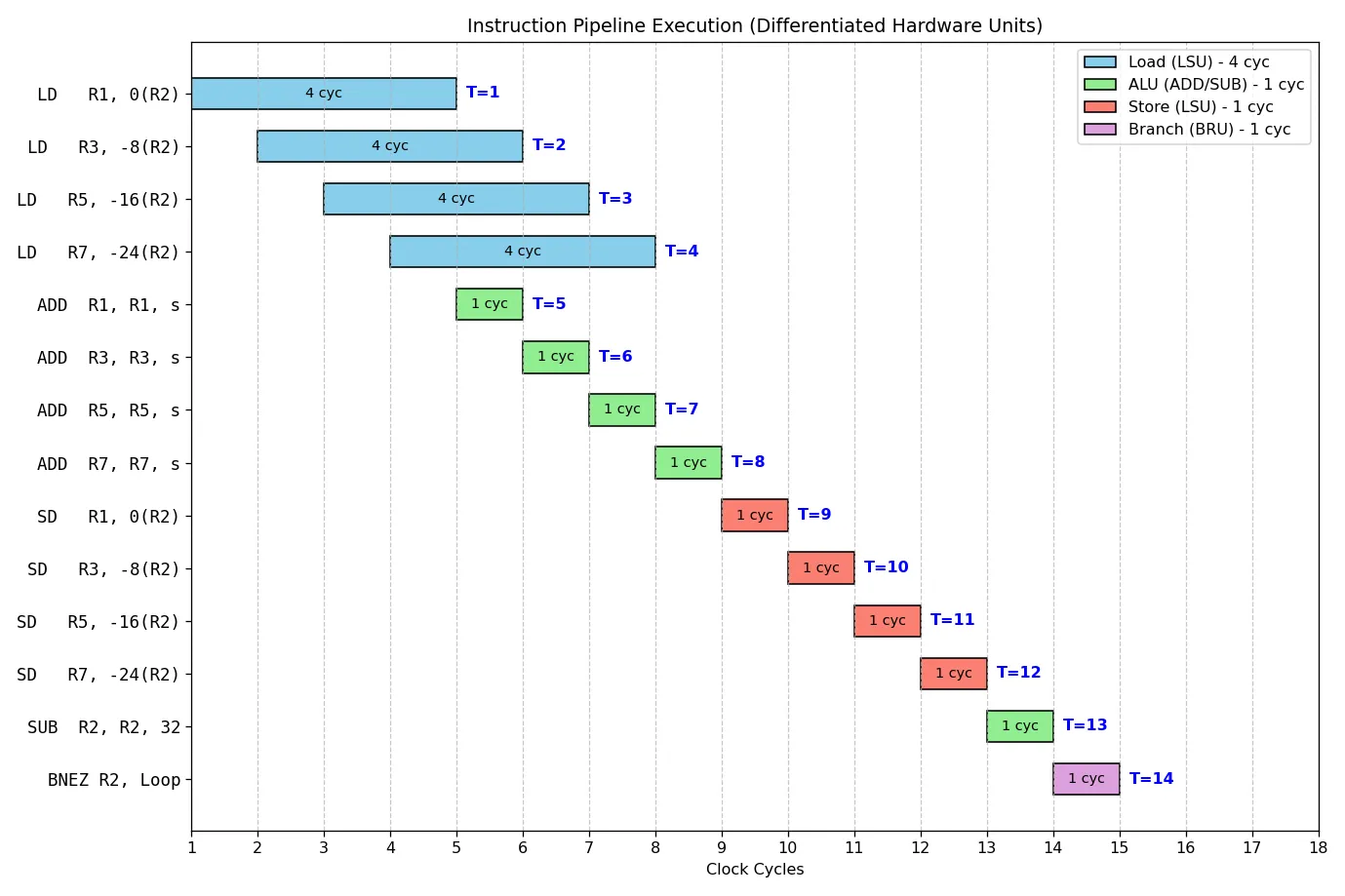
Loop: ; 【阶段 1:集中加载,填补 Load 气泡】 LD R1, 0(R2) LD R3, -8(R2) LD R5, -16(R2) LD R7, -24(R2) ; 【阶段 2:集中计算,此时前面的数据会陆续准备好】 ADD R1, R1, s ADD R3, R3, s ADD R5, R5, s ADD R7, R7, s ; 【阶段 3:集中写回】 SD R1, 0(R2) SD R3, -8(R2) SD R5, -16(R2) SD R7, -24(R2) ; 【阶段 4:只做一次循环维护】 SUB R2, R2, 32 BNEZ R2, Loop在**单发射(Single-issue)**的情况下,延迟被紧紧地压在了指令之间。此时我们需要 14 个时钟周期来处理 4 个元素,平均每个周期处理 0.28 个元素。这距离我们得出的理论极限(ResMII = 1)还差得很远。
然而,现代 CPU 几乎都是超标量结构,具备多发射、乱序执行以及寄存器重命名等 “黑科技”。回到我们刚刚的硬件假设中(4 个 ALU、2 个读口、1 个写口、1 个分支单元),你会发现代码的实际运行状态其实是这样的:
你会惊奇地发现,我们之前绞尽脑汁试图消除的流水线停顿(Stall)在某些地方又 “回来” 了;但同时,乱序执行和多发射机制让指令执行大幅提前。在展开步幅 为 4 时候,最终的运算在 9 个时钟周期后就完成了。
9 个周期处理 4 个元素,平均每个周期处理 0.45 个元素。虽然效率已经极高,但距离 ResMII 理论上的 “每周期处理 1 个元素”,仍有一半的差距。
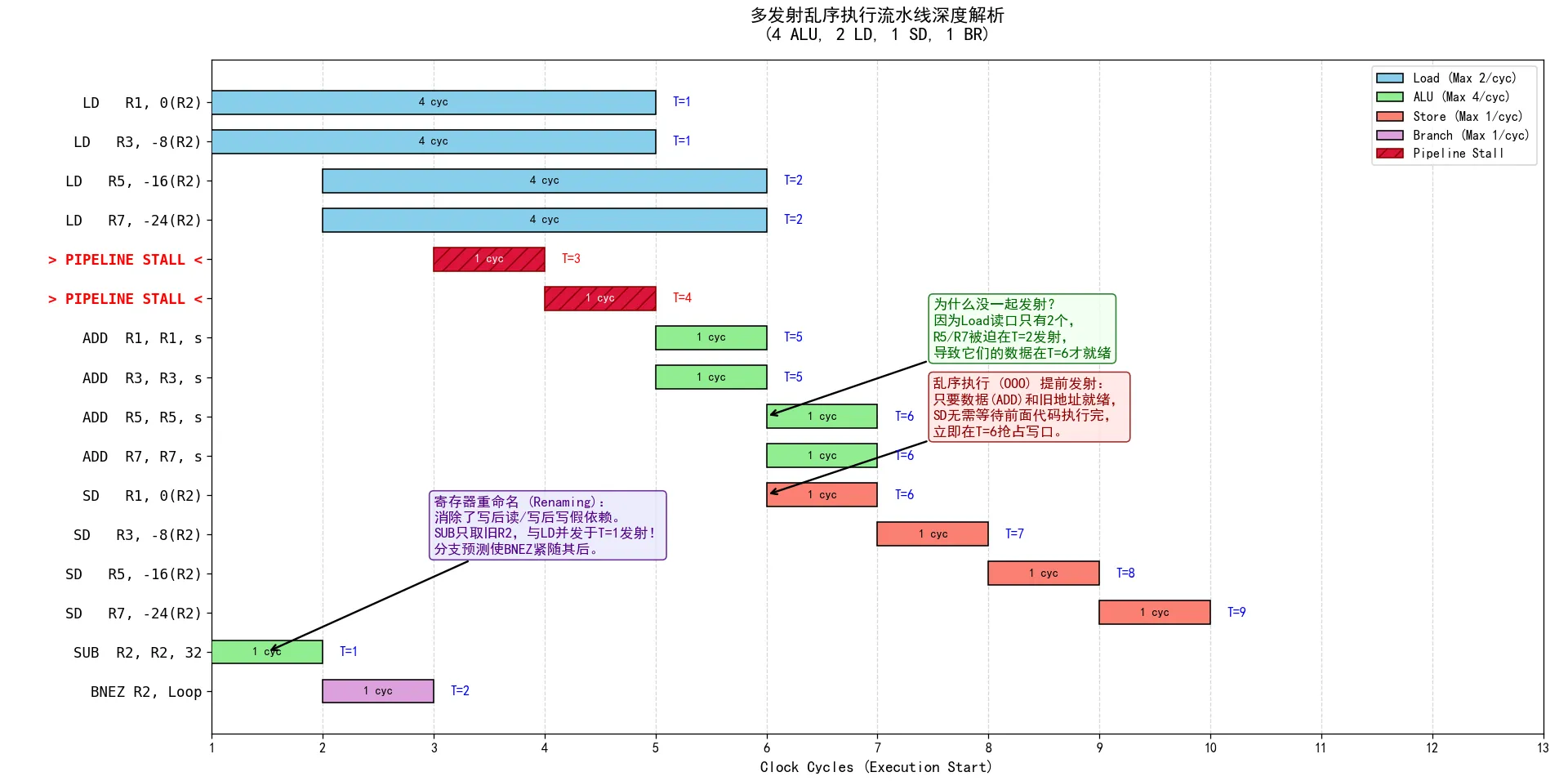
简而言之,OoO和SuperScalar等硬件黑科技的引入反而再次导致了Stall,虽然说整体的完成时间周期变短了。既然如此,我们肯定会尝试思考如何优化掉这些Stall。一个显然的思路是:增加循环展开的次数(在没有引入硬件黑科技时,我们通过循环展开消除了Stall)
理论上可以:展开 次后,指令构成会变为: 个
LD、 个ADD、 个SD、1 个SUB和 1 个BNEZ。在充分调度的理想状态下,执行这些指令的成本如下:- 发射 LD: 拥有 2 个内存读口,发射 个
LD需要 个周期。 - 算术依赖掩盖: 所有的
ADD依赖前面的LD。但当 (这里取5是因为LD需要4个周期)时,多出来的并行度足以把 Load 延迟完美掩盖,无需等待。 - 发射 ADD: 拥有 4 个 ALU 单元,发射 个
ADD需要 个周期。 - 写回依赖掩盖: 同理,
SD依赖前一条ADD。只要 足够大,延迟同样会被完全掩盖。 - 发射 SD: 这是关键瓶颈!内存写口只有 1 个,所以发射 个
SD必须硬扛 个周期。 - 循环控制:
SUB和BNEZ会被乱序执行引擎在合适的周期内悄悄消化掉,耗时可忽略不计。(具体可以参考上述的图)
原文提及:
因为 CPU 具有乱序执行和硬件流水线能力, 个周期的
LD和 个周期的ADD可以完美重叠,并被隐藏在耗时最长的 个SD周期中。这里比较疑惑,因为根据上述的图,不难得到
ADD只有等待先前对应的LD完成后才能执行完毕,这里的完美重叠可能指的是:两者都能隐藏在个SD周期中。因此,执行这一轮展开后的总时间约等于:
展开 次意味着一次循环处理 个元素,那么平均处理单个元素的启动间隔(II, Initiation Interval)就是:
从公式可以看出,随着 的趋近于无穷大,整体的启动间隔会无限逼近理论极限 ResMII(也就是 1)。
- 发射 LD: 拥有 2 个内存读口,发射 个
现实中不行:两大工程悖论阻挡了无限展开:
- 寄存器溢出:展开需分配新寄存器消除依赖。硬件寄存器有限(如ARM32仅16个),超出后数据必须暂存内存(把中间数据暂存到内存(栈)中,然后再从内存中读出来),引发Cache Miss,性能断崖式下跌。
- 指令缓存缺失:展开导致代码体积急剧膨胀,超出L1 I-Cache容量,触发指令缓存缺失(Instruction Cache Miss),CPU取指令停工数百周期,抹平优化收益。
终极杀器:软件流水线
1. 核心思想:错位重组(寅吃卯粮)
打破原循环“读-算-写”的顺序边界,让同一个循环体内并行执行不同迭代阶段的任务。(更通俗地讲:抓住各个循环体之间相互独立的特点,打乱各个循环体的指令顺序的同时,保证每个循环体内容的指令顺序不变,即内部顺序不变,外部顺序改变)。
补充下原文的例子:
在正式讨论之前,我们再回到最初的汇编代码。仔细观察你会发现,这套动作里唯一 “拖后腿” 的不和谐因素,就是那条带有 4 周期延迟的
LD指令。Loop: LD R1, 0(R2) ; 不和谐处,只有这个指令的执行延迟是4 ADD R1, R1, s SD R1, 0(R2) SUB R2, R2, 8 BNEZ R2, Loop我们再细观察一下,每个循环体都包含了
LD、ADD和SD三个核心动作,以及用于维护循环的指针递减和条件跳转指令。并且,LD在前、ADD在中、SD在后的执行顺序,是典型的写后读(RAW)数据依赖。注意:RAW 是算法逻辑的内在属性,天王老子来了也改变不了它们执行的先后顺序。
解决方法:错位重组。在同一个循环体内,存(SD) 第 个元素的结果,算(ADD) 第 个元素,读(LD) 第 个元素的内容。利用其他指令的耗时完美掩盖LD的4周期延迟。
SD ADD LD SUB BNZE粗略估算一下此时的周期:从
LD发射(读取第i+2个元素),到下一次循环的ADD去使用它的值,中间刚好隔了SUB、BNEZ以及下一次循环开头的SD,完美掩盖LD的4周期延迟。不过需要注意如下两个事项:- 需要提前把最前面的几个元素提前读取和计算好,后续才能正式进入这种错位状态。对应下面的序言。
- 错位状态结束时,完成剩余的计算和存储任务,需要在循环体外部进行收尾。对应下面的排空。
原文给出最终的形态如下:
; ==========================================
; 【阶段 1:序言 (Prologue)】 - 预热流水线
; ==========================================
LD R1, 0(R2) ; 取第 1 个元素 (i=0)
; 这儿会有 3 个周期的硬件 Stall 等待 LD 结果,但整个程序仅发生这一次
ADD R3, R1, s ; 算第 1 个元素 (i=0)
LD R1, -8(R2) ; 读第 2 个元素 (i=1)
; ==========================================
; 【阶段 2:稳态循环 (Steady State)】 - 全速运行,掩盖延迟
; ==========================================
Loop:
SD R3, 0(R2) ; [写回] 写入第 i 个元素的结果
ADD R3, R1, s ; [计算] 计算第 i+1 个元素
LD R1, -16(R2) ; [读取] 读取第 i+2 个元素
SUB R2, R2, 8 ; 指针维护(注意:每次依然只前进 1 个元素)
BNEZ R2, Loop ; 循环条件检测
; ==========================================
; 【阶段 3:排空 (Epilogue)】 - 处理收尾工作
; ==========================================
SD R3, 0(R2) ; 写入倒数第 2 个元素
ADD R3, R1, s ; 计算最后 1 个元素
SD R3, -8(R2) ; 写入最后 1 个元素没有考虑硬件的多发射和乱序执行的情况如下:
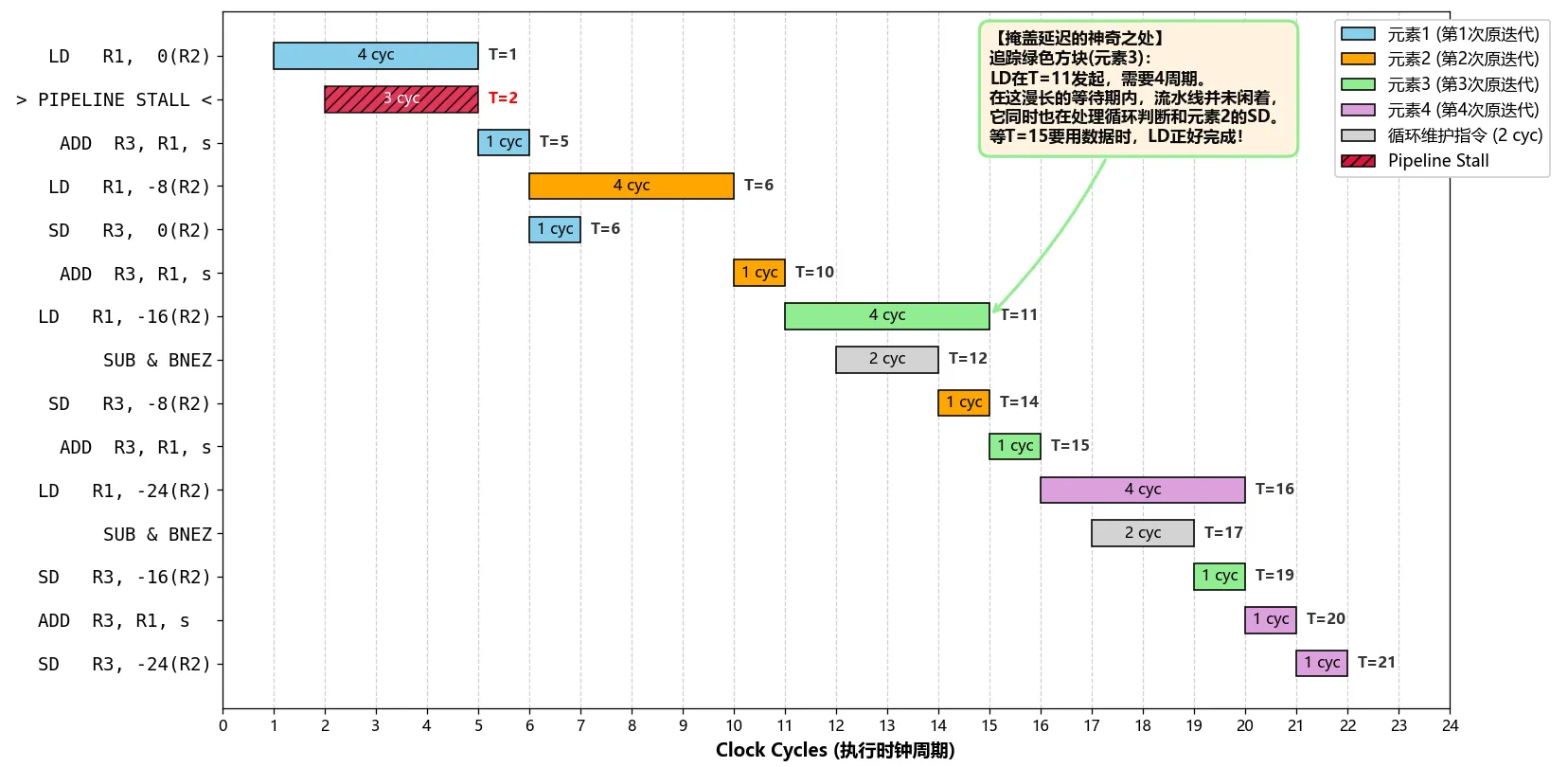
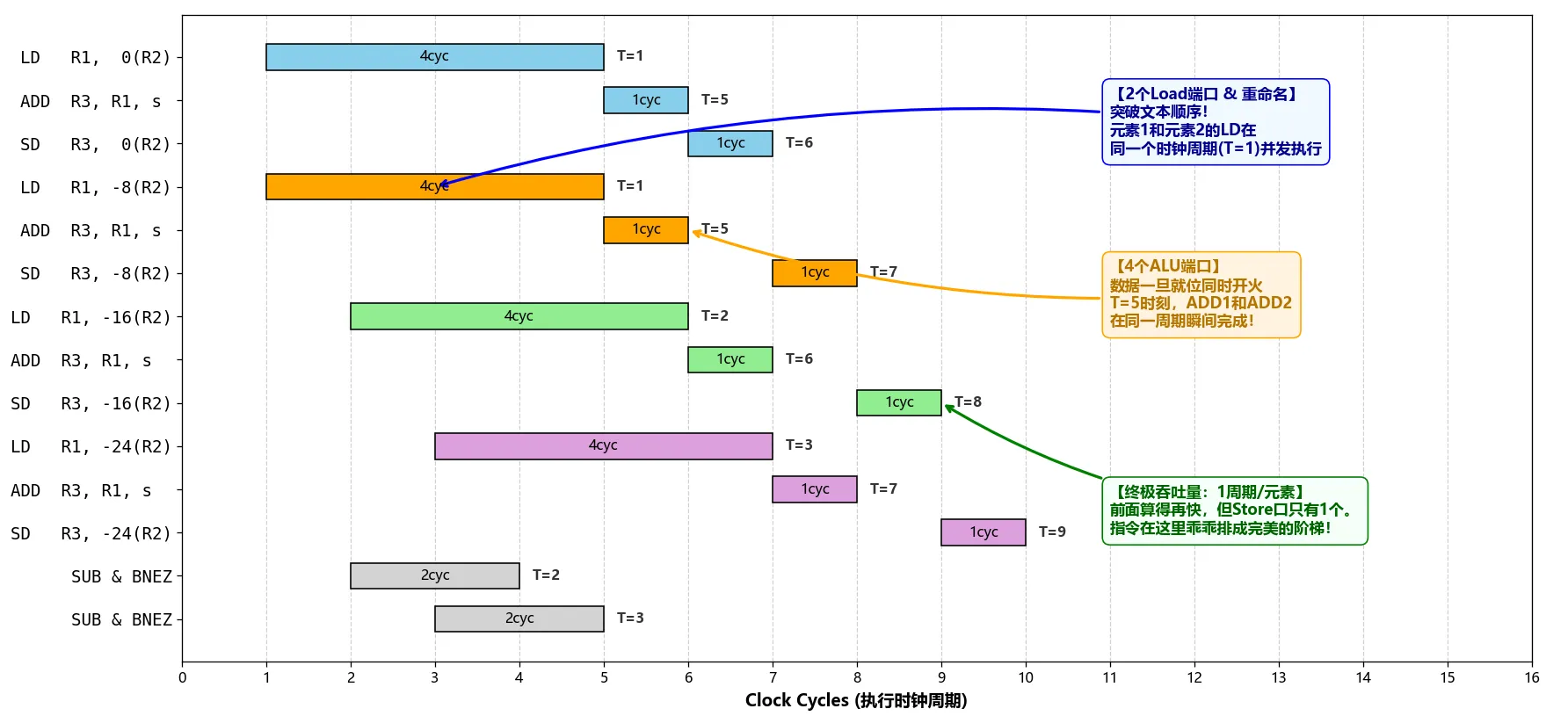
考虑硬件的多发射和乱序执行的情况如下:
2. 软件流水线的三个阶段
- 序言(Prologue):预热流水线。提前读取和计算最前面的元素,让流水线“丰满”起来。
- 稳态循环(Kernel):全速运行。核心的“存、算、读”错位执行,吞吐量拉满。
- 排空(Epilogue):收尾工作。处理稳态中遗留的最后几次计算和存储任务。
3. 定量分析与寄存器优势
这里的执行时间分析还是使用上述的例子:
我们在来定量分析一下软件流水线的执行效率问题(上一节其实已经给了结论了,不喜欢的同学,可以自行跳过 ^_^)。整个软件流水线的分成三个阶段:
注:如下的计算会和不同 CPU 下的实际执行流程稍有出入。但是为了方便理解,我还是会依据汇编代码和硬件特性本身来定量逻辑分析。这儿笔者预设:
- 多发射宽度大于 5。
- 完全不考虑 cache miss 的情况,也就是说 LD 指令始终是 4 周期延迟,SD 始终是 1 周期延迟。
- 硬件支持 “寄存器重命名”,这意味着所有的输出依赖(WAW)和反依赖(WAR)都能被掩盖。
- 序言阶段(Prologue):一共有两个读指令一个写指令,硬件上有两个读口,所以这个阶段需要 5 个时钟周期,代码如下:
LD R1, 0(R2) ; 指令一:“读”第1个元素 ADD R3, R1, s ; 指令二:“算”第1个元素 ; 它跟指令一形成了“读后写”数据依赖 ; 所以必须在指令一完成以后才能执行 LD R1, -8(R2) ; 指令三:“读”第2个元素 ; 它跟指令一形成了“写后写”输出依赖 ;所以硬件的“寄存器重命名”技术能把它和"指令一"一起执行
- 稳态阶段(Kernel):一共有五条指令,一个 SD,一个 LD,两个 ALU,一个分支判断,同时完美的避开了硬件上的资源冒险。所以每个阶段都需要执行 4 个执行周期(LD 是最长的那个版子,所以都以它为准)。但是特殊的地方在于,连续的执行会自然形成一个流水线,借助硬件流水线的执行能力,每个周期弹出一个成品(SD 执行完)。因为总共有 N 个元素,剩下的元素都在稳态中 1 周期 1 个地弹出来。耗时 N−1 个周期。(注意:最终退出 Kernel 状态后,还需要处理剩余的情况,所以这里只能完成 N-1个)
SD R3, 0(R2) ; 指令一:写入第 i 个元素的结果 ADD R3, R1, s ; 指令二:计算第 i+1 个元素 ;它跟指令一形成了“写后读”反依赖 ;所以硬件的“寄存器重命名”技术能把它和指令一一起执行 LD R1, -16(R2) ; 指令三: 读取第 i+2 个元素 ;无依赖,直接被多发射“见缝插针”了 SUB R2, R2, 8 ; 指令四:调整循环变量 ;它跟指令一形成了“写后读”反依赖 ;所以硬件的“寄存器重命名”技术能把它和指令一一起执行 BNEZ R2, Loop ; 指令五:循环判断 ;它跟指令四形成了“读后写”数据依赖 ;所以需要在指令四完成以后才能执行
- 排空阶段(Epilogue):一共三条指令,考虑到数据依赖和资源冒险,一共需要 2 个时钟周期。
SD R3, 0(R2) ; 指令一:写入倒数第 2 个元素 ADD R3, R1, s ; 指令二:计算最后 1 个元素 ;跟指令一是“写后读”反依赖 ;所以硬件的“寄存器重命名”技术能把它和指令一一起执行 SD R3, -8(R2) ; 指令三:写入最后 1 个元素 ;它跟指令二形成了“读后写”数据依赖 ;所以需要在指令二完成以后才能执行
- 最终执行时间公式:。
- 平均单元素时间:。当 足够大时,无限逼近理论极限 。
- 寄存器优势(关键):
- 循环展开:寄存器消耗随展开次数 线性暴增,极易溢出。
- 软件流水线:寄存器消耗是固定的(不随元素数量 增长),仅随流水线重叠深度成倍增加。在压榨吞吐与控制寄存器压力之间取得了更优平衡。
软件流水线的局限性(不是银弹)
1. 对输入规模 (N) 要求高
当 很小时,序言和排空的开销(+6)占比过大,平均时间飙升,甚至比不优化还慢。
- 解法:编译器通常生成两套代码,运行时判断 大小来选择执行路径(增加分支开销)。
2. 代码膨胀问题
原5条指令变为“序言+稳态+排空”三部分,代码体积翻倍,同样可能引发 I-Cache Miss。
- 引申:因此需要 PGO(Profile-Guided Optimization,基于反馈的编译优化) 来指导优化决策。
3. 循环间依赖的致命制约
如果迭代间存在强依赖(如 A[i] = A[i-1] * s),第 次必须死等 次结果,流水线无法“错位重组”,软件流水线失效。当然也存在解决方法,后续会介绍。
4. 对控制流极其敏感
循环体内若有 if-else、break、continue:
- 需引入谓词指令增加复杂度。
break/continue会导致提前“预取/预计算”的 迭代作废或引发越界非法访问(Segment Fault),导致软件流水线直接“宕机”。
结语与启发
无论是循环展开还是软件流水线,本质都是用“空间”(寄存器/代码体积)换“时间”(掩盖延迟)。这也催生了追求极致性能的高级开发思维:
- 面向数据设计(DOD)
- 无分支编程
- 机械同理心:让软件代码与底层微架构做朋友,懂底层才能写出有灵魂的代码。