【硬核体系结构与编译器技术】循环间依赖与双剑合璧的破局之道
概述
当循环存在循环间依赖时,单纯依靠软件流水线无法突破数据依赖的锁链(墙)。此时必须祭出**“循环展开 + 软件流水线”**的双剑合璧打法:通过循环展开切断/缩短依赖链条,再由软件流水线填平延迟气泡,才能逼近硬件理论极限。面对更复杂的多层嵌套循环,则需要引入循环重排、切块、多面体模型等更高级的优化技术。
循环间依赖与 RecMII 墙
1. 什么是循环间依赖?
与每次迭代互不干扰的 DoAll Loop 不同,现实中很多代码的后一次迭代强依赖前一次迭代的结果:
// 场景一:累加求和(Reduction)
float sum = 0;
for (int i = 0; i < 1000; i++) {
sum = sum + x[i]; // 第 i 次的 sum,强依赖第 i-1 次的结果
}
// 场景二:递推序列
for (int i = 1; i < 1000; i++) {
A[i] = A[i-1] * s; // 算 A[i] 必须等 A[i-1] 算完写回
}这像一根隐形锁链,把迭代死死绑在一起。
2. 依赖最小启动间隔
仅仅关注硬件资源(ResMII)不够了,必须引入由数据依赖环路决定的 RecMII(Recurrence Minimum Initiation Interval,依赖最小启动间隔)。
计算公式:
- 执行延迟:完成一次依赖计算需要的时钟周期(如浮点加法需3周期)。
- 依赖距离:依赖跨越了几个循环迭代(如第 次依赖 次,距离为1)。
性能天花板公式:
案例:这里以累加求和为例
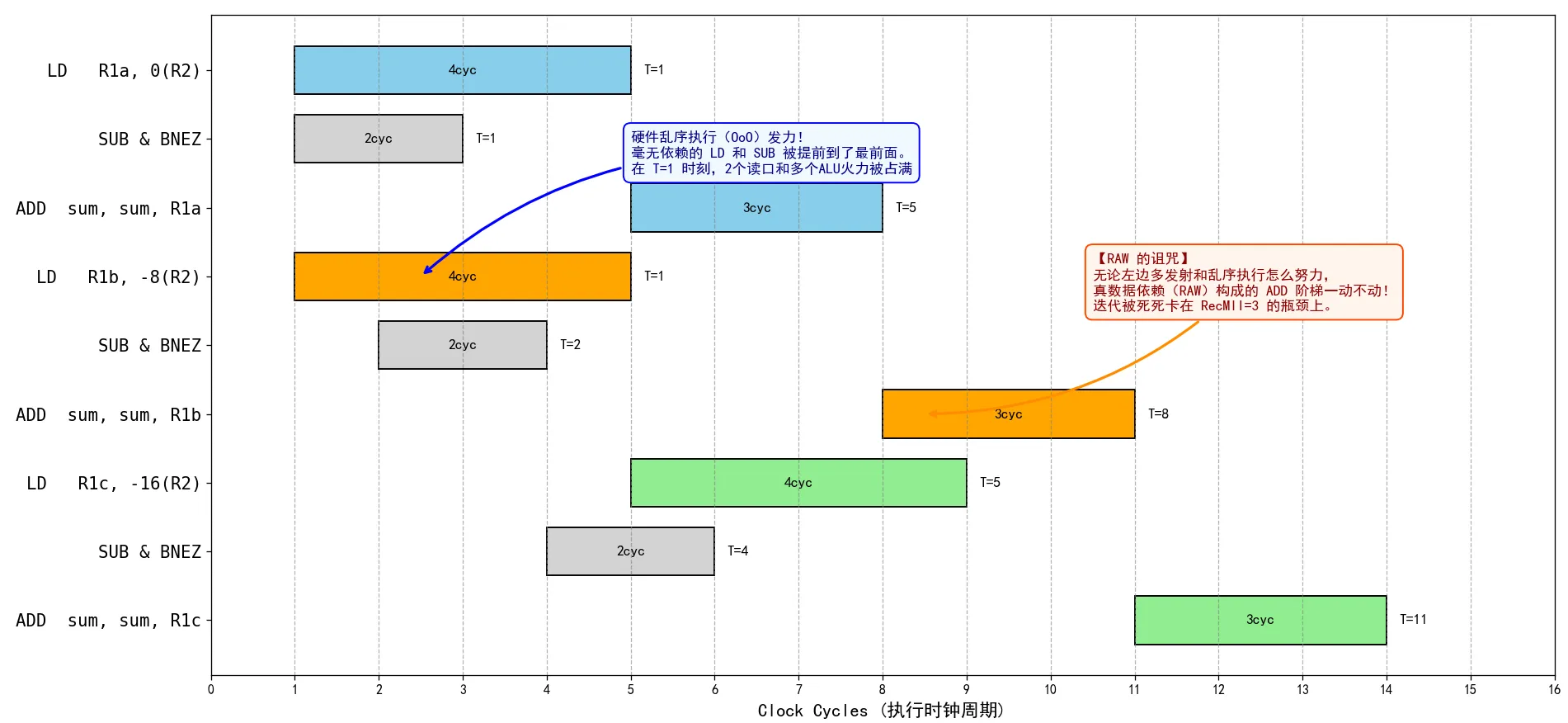
Loop: LD R1, 0(R2) ; 读 x[i] (假设需要 4 周期) ADD R_sum, R_sum, R1; sum = sum + x[i] (浮点加法假设需要 3 周期) SUB R2, R2, 8 ; 指针维护(注意:每次依然只前进 1 个元素) BNEZ R2, Loop ; 循环条件检测首先考虑依赖距离的计算:第 次的 必须等第 次的 算完。跨越了 1 次迭代,所以依赖距离 = 1。
笔者注:当然,依赖距离的计算不可能都这么简单,后续我将起个番外篇来说说依赖距离问题,请持续关注。
- 其次我们看延迟:选取CPU中带有寄存器重命名的动态版本来分析,如下:
; ----- 第 i 次迭代 ----- LD R1a, 0(R2) ; 指令 A1 ADD R_sum, R_sum, R1a; 指令 B1 (需要 R1a,同时也需要上一轮的 R_sum) ; ----- 第 i+1 次迭代 ----- LD R1b, 8(R2) ; 指令 A2 ADD R_sum, R_sum, R1b; 指令 B2 (需要 R1b,同时也需要上一轮的 R_sum)指令A1和指令A2无依赖关系,所以他们可以并行发射(这里本来是一个“写后写”相关(WAW),但是硬件的重命名把这类输出相关抹除了,我们看到的直接是抹除后的效果);但是指令B1和指令B2 以及指令A1是典型的“读后写”数据依赖关系,所以指令 B2必须在指令 B1和指令A1后执行。
- 我们先来分析指令B2和指令B1的关系,它们都是ALU类型的指令,而且存在RAW依赖,那么它们必须排队,执行延迟是浮点运算的延迟3。
- 再来分析指令B2和指令 A2的关系,它们虽然也存在RAW依赖关系,但是一个是ALU类型指令、一个是访存类指令,所以可以提前发射LD指令,在ADD需要数据之前就把数据LD到位。执行延迟为0。
浮点加法延迟3,依赖距离1,则 。系统瓶颈撞上了“数据依赖墙”。
3. 为什么软件流水线也没招?
软件流水线能藏起“访存延迟”,但无法打破RAW(读后写)的真数据依赖。下一轮的加法必须死等上一轮加法算完,形成不可压缩的“阶梯”,硬件再多ALU也只能干瞪眼。
破局:双剑合璧(循环展开 + 软件流水线)
面对 RecMII 墙,编译器必须让“循环展开”重返战场,与“软件流水线”打出组合拳。首先补充下原始例子:
// 场景一:累加求和(Reduction)
float sum = 0;
for (int i = 0; i < 1000; i++) {
sum = sum + x[i]; // 第 i 次的 sum,强依赖第 i-1 次的结果
}策略一:多路累加器扩展(降低 RecMII)
痛点:所有迭代抢同一个累加器(寄存器),导致依赖距离为1,RecMII极高。
解法:在数学结合律允许下,展开循环并引入多个独立累加器。
原始:
sum = sum + x[i]()展开2次:
sum1 = sum1 + x[i]; sum2 = sum2 + x[i+1](一次处理2元素,)// 原始串行链条 // sum = sum + x[0] + x[1] + x[2] + x[3] + ... // 【展开 2 次】后:劈成两根平行的短链 float sum1 = 0, sum2 = 0; for (int i = 0; i < 1000; i += 2) { sum1 = sum1 + x[i]; // 链条 1 sum2 = sum2 + x[i+1]; // 链条 2 } sum = sum1 + sum2; // 循环外收尾展开4次:劈出4条平行链 ()
结果: 降到 0.75,低于 ,系统瓶颈从数据依赖重新回到硬件资源极限,MII = 1,突破瓶颈!
策略二:展开缩短依赖距离(解决寄存器踩踏)
痛点:对于长距离依赖(如
x[i] = x[i] + x[i-3],距离为3),理论上 ,看似完美。但实际上,物理寄存器有限,编译器会复用寄存器作为中转踏板。若按 II=1 排布软件流水线,前一轮结果还没算完,后一轮就想读该寄存器,引发**“连环踩踏”**。; ----- 原始单次循环体的伪汇编(未展开) ----- ; 假设 R_prev 存放着 3 个迭代前算好的 x[i-3] ; 假设 R_curr 用来存放刚刚加载的 x[i] Loop: LD R_curr, 0(R_addr) ; 指令 A:加载当前 x[i] ADD R_res, R_curr, R_prev ; 指令 B:核心加法!耗时 3 个周期,算出新 x[i] ST R_res, 0(R_addr) ; 指令 C:将算好的新 x[i] 存回内存 ... (指针递增、跳转等控制指令)这个地方介绍的很抽象,在我看来这个地方的主要问题是:寄存器的数量有限,编译器会复用有限的寄存器作为结果中转的踏板。很显然的方法就是使用循环展开解决这个问题。
解法:循环展开,为不同链条分配不同的物理寄存器作踏板。
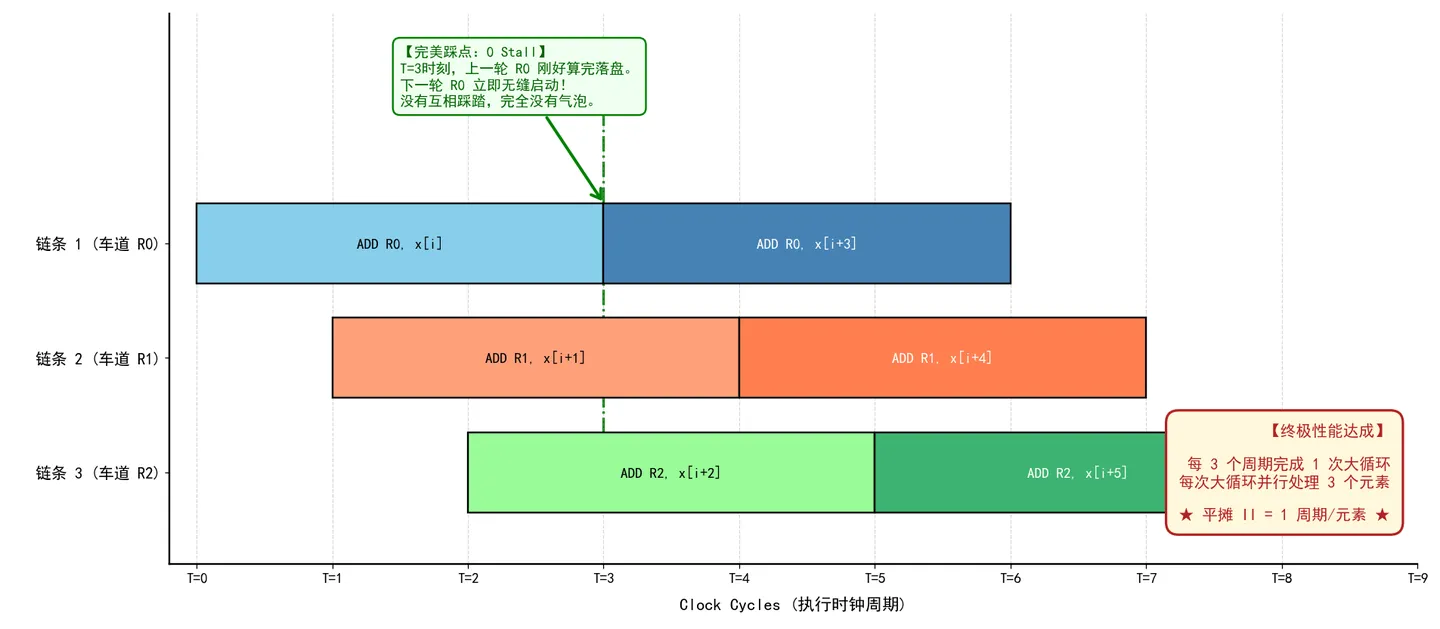
展开3次,分配 R0, R1, R2 分别处理
x[i],x[i+1],x[i+2]。// 【展开 3 次】后:劈成三根平行的独立短链 for (int i = 3; i < 1000; i += 3) { // 链条 1(分配给物理寄存器 R0) x[i] = x[i] + x[i-3]; // 对应伪汇编: R0 = R0 + LOAD(x[i]) // 链条 2(分配给物理寄存器 R1) x[i+1] = x[i+1] + x[i-2]; // 对应伪汇编: R1 = R1 + LOAD(x[i+1]) // 链条 3(分配给物理寄存器 R2) x[i+2] = x[i+2] + x[i-1]; // 对应伪汇编: R2 = R2 + LOAD(x[i+2]) }
效果:空间冲突被多寄存器化解。展开后,新大循环的依赖距离缩短为1, 变回 3。虽然单次大迭代耗时变长,但一次处理3个元素,配合软件流水线的指令调度和硬件多发射,稳态阶段依然达到了**“1周期/元素”**的巅峰极限。
img
多层循环的前瞻与终极武器
单层循环的优化到此极致,但深度学习中多是多层嵌套循环:
//一个经典的动态规划场景
for (int i = 1; i < N; i++) {
for (int j = 1; j < M; j++) {
// 每个点都要等待它的“正上方”和“正左方”算完
A[i][j] = A[i-1][j] + A[i][j-1];
}
}此时单层优化策略瞬间哑火,面临交叉依赖网和内存墙双重暴击。必须引入更高维度的技术颠覆:
原文中关于交叉依赖网和内存墙的描述如下:
- 更复杂的交叉依赖:这里的依赖不再是一根单向的铁链,而是一张纵横交错的网。你往横向(j)展开,会撞上纵向(i)的依赖;反正,你往纵向展开会撞上横向的依赖。这个时候循环展开加上软件流水线的复杂程度会指数级增加。就算最后侥幸成功了,你需要的“序言”和”排空”时间以及面对的寄存器压力也会比现在大很多。得不偿失!
- 内存墙问题的凸显:在一维循环中,我们只关心 ALU 够不够、端口够不够。但在多维大矩阵中,数据可能根本就装不进 L1 Cache;更严重的如果你内存的访问顺序不对,引发了大量的 Cache Miss,最终的效果就会是大量的”计算单元“被闲置(这个现象在NPU或者TPU上更为致命)。你会发现,这个时候CPU上那一套靠硬件根据“数据局部性”原理构建出来的、主动“猜测”哪些内存应该被缓存的管理法则,根本就不奏效了。所以,哪怕你的软件流水线排得再完美,微处理器也得原地罚站几百个周期等着从主存里捞数据。
- 循环重排(Loop Reorder):
- 交换内外层循环,改变数据访问顺序,使其符合内存布局(如C语言行优先),避免 Cache Miss,性能可提升几倍到几十倍。
- 循环切块(Loop Tiling / Blocking):
- 当矩阵大至塞不进 Cache 时,将大遍历空间切分成刚好能塞进 L1/L2 Cache 的“小方块”,算完一块再算下一块。这是 OpenBLAS、cuBLAS 的核心立足之本。
- 数据级并行(DLP / SIMD 向量化):
- 标量计算吞吐量见顶,需利用超宽向量寄存器(AVX-512等)或 GPU/NPU,实现一条指令处理多个数据**。**
- 多面体模型(Polyhedral Model):
- 应对错综复杂的交叉依赖。抛弃线性代码观念,将多维循环映射为高维空间的几何多面体,数据依赖变成空间向量。通过仿射变换(如倾斜 Skewing、切块、重排),在高维几何空间中像揉面团一样打破依赖枷锁。
总结与启示
- 循环展开斩断数据锁链,软件流水线填平延迟气泡,二者是精确配合的绝代双骄。
- 现实代码的结构(控制流、指针别名、循环依赖)直接决定了编译器敢不敢、能不能施展优化魔法。
- 这也是为何追求极致性能的领域会诞生面向数据设计(DOD)和机械同理心,懂底层才能写出有灵魂的代码。