【硬核体系结构与编译器技术】CPU的画像与资源天花板的量化——ResMII
概述
CPU 的单核算力存在物理天花板,这个天花板由其硬件资源数量和**执行逻辑(流水线/多发射)**共同决定。在编译器优化中,为了量化这个天花板,引入了 ResMII(资源最小启动间隔) 概念。它告诉我们在不考虑数据依赖的理想情况下,硬件资源允许循环迭代达到的最快启动频率。
CPU 的硬件组成:工厂的“硬通货”
CPU 就像一个分工明确的超级工厂,核心物理资源分为两类:
1. 执行单元(Functional Units / Execution Ports)
专门负责计算和访存的硬件电路,且每类单元有多个物理实体:
- ALU:负责基础整数运算。
- FPU:负责复杂浮点运算。
- LSU:负责和内存打交道(Load/Store)。
- 案例:Intel Skylake 微架构有 8 个执行端口,包含 4 个 ALU、2 个 Load 单元、1 个 Store 单元。这意味着单周期内,物理上最多只能做 4 次整数运算或 2 次内存读取。
2. 寄存器文件(Register File)
距离计算单元最近、速度最快的存储介质(延迟 01 周期,远超 L1 Cache 的 45 周期和 DRAM 的 200~300 周期)。最紧缺、最昂贵。
- 隐藏的物理寄存器:ISA 暴露给程序的逻辑寄存器很少(如 x86-64 只有 16 个通用寄存器),但底层为了榨取性能(寄存器重命名消除假依赖),存在庞大的物理寄存器文件(如 Skylake 有 168 个整数 + 168 个浮点物理寄存器)。
CPU 的执行逻辑:时空维度的压榨
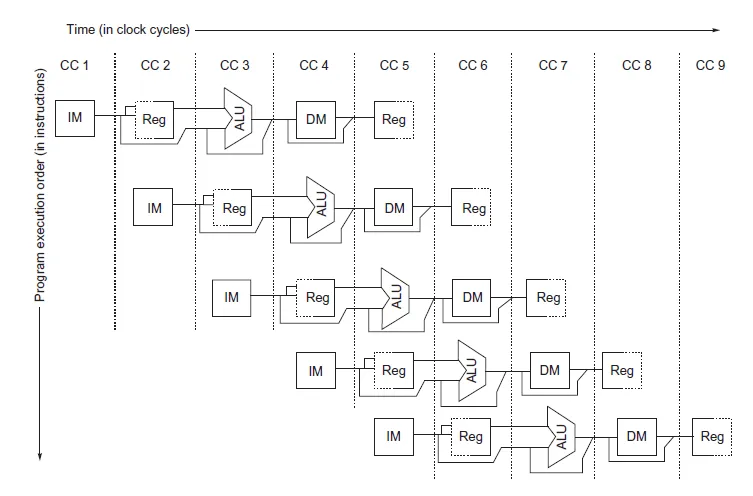
1. 硬件流水线(Hardware Pipeline)—— 时间维度的重叠
思想:将指令执行拆分为多个级(如经典的五级:取指令(Fetch)、译码(Decode)、执行(Execute)、访存(Mem Access)、写回(Write Back)),像干洗店洗衣服一样“见缝插针”,不同指令的不同阶段重叠执行。
img 两大指标:
- 吞吐量(Throughput):一个关键指标是IPC(Instructions Per Cycle),即流水线填满后,每周期完成的指令数(理想为 1)。
- 指令延迟(Latency):
- 端到端延迟:指令从进入 CPU 到完成的总周期(如 ADD 需 4 周期,浮点乘需 7 周期)。
- 执行延迟:由于流水线掩盖了前期步骤,看起来指令产出的间隔(如 ADD 执行延迟为 1,FMUL 为 4)。通常“指令延迟”指执行延迟。
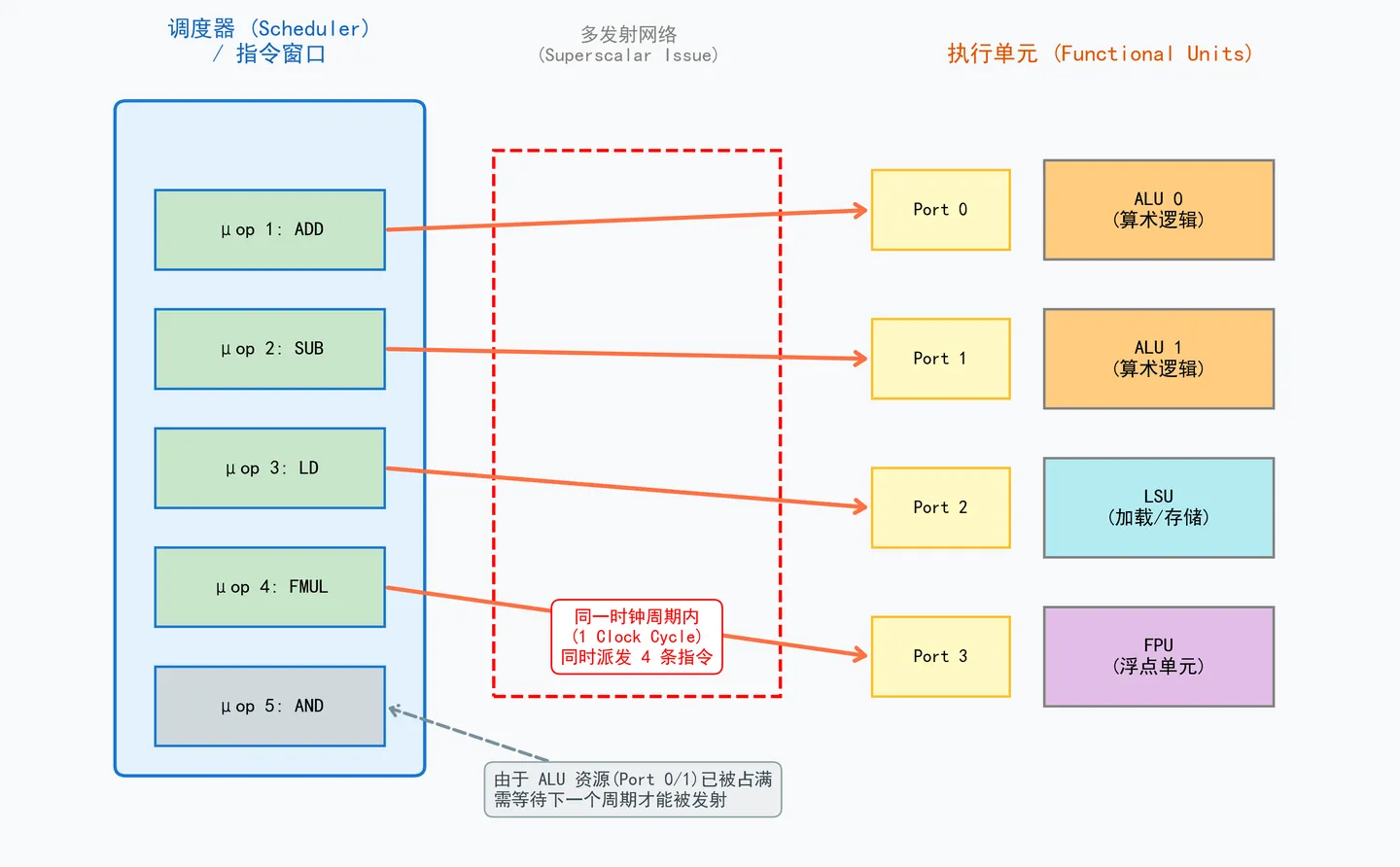
2. 多发射与超标量(Superscalar / Multiple Issue)—— 空间维度的并行
- 思想:配置更多的运算设备(多 ALU/LSU),调度器在同一个时钟周期内,将多条相互独立、无数据依赖的指令同时发射到空闲端口执行。
- 本质:流水线让同一单元“一拍接一拍”干;多发射让不同单元“并驾齐驱”干。
注意,这里虽然有更多的运算单元,但是也需要考虑如何编排工作流程,该项任务由CPU中的**调度器/派发单元(Scheduler / Dispatch Unit)**主导。
现代 CPU 绝大多数都是超标量(Superscalar)架构。你可以把发射单元想象成一个极速的分拣中心,它会实时盯着前面排队等待执行的指令窗口(Instruction Window)。如果它发现队伍里有几条指令是相互独立、没有数据依赖的,并且后端对应的执行端口(Port)刚好空闲,它就会在同一个时钟周期内,把这多条指令同时“发射”(Issue)下去!
资源天花板的量化:ResMII(Resource Minimum Initiation Interval)
无论流水线多丝滑、发射多宽,物理资源总有限。引出核心问题:
如果我想让循环的吞吐量尽可能高,硬件资源本身允许我做到多快?
1. 启动间隔(Initiation Interval)
定义:相邻两次启动循环迭代之间的最小周期数。(该概念由软件流水线(Software Pipelining)和modulo scheduling引入,可以后续了解modulo scheduling)
与吞吐量的关系:
II 越小,吞吐量越大。
与 CPI 的区别:CPI 衡量单条指令,II 衡量整个循环体。II 在编译优化中有明确的“锚点”(具体的循环体),在编译优化中比 CPI 更具实操意义。
2. ResMII 的定义与计算
定义:仅由硬件资源约束决定的 II 的理论下界(假设完全无数据依赖)。
计算公式:遍历所有硬件资源种类,计算各资源的约束,取最大值(木桶效应)。
对于每种资源 :
综合所有资源:
(注: 表示向上取整,因为CPU不能等半拍)
3. 计算案例演示
案例 1:常规运算
代码:
for (int i = 10000; i>0 ; i--) { A[i] = B[i] + C[i] + D[i] + E[i] }一个迭代实际上包含了如下8条指令:4次Load, 3次Add, 1次Store。
硬件:
- 每个周期最多调度8条指令(指令窗口是8)
- 每周期最多 2 个 Load(2 个 Load port)
- 每周期最多 4 个整数 ALU op(4 个 ALU)
- 每周期最多 1 个 Store(1 个 Store port)
计算:
- Schedule:
- Load: (瓶颈!)
- ALU:
- Store:
结论:
最快只能每 2 个周期启动一次迭代。
案例 2:包含不可流水线指令(如除法)
代码:
for (int i = 10000; i>0 ; i--) { A[i] = (B[i] + C[i] + D[i]) / E[i] }一次迭代实际上包含了如下8条指令:4次Load, 2次Add, 1次DIV, 1次Store。
不可流水线指令的影响:由于除法器无法流水化,它霸占除法器的时间等于其端到端延迟(假设 10 周期)。此时该资源的占用需乘以延迟。
计算:
其他的照常不变
结论:
一颗老鼠屎坏了一锅粥!
4. 两大规律总结
- ResMII 的计算同时依赖于微处理器的资源上限和循环体本身的指令构成。
- 启动间隔的理论下界只取决于最紧缺的那个资源(最大值)。(这也是为什么“强度削弱”——把除法/乘法替换为移位/加法——是编译器优化的核心手段之一)
终极公式预告
ResMII 只考虑了资源限制,现实中还有循环间数据依赖的限制。最终的启动间隔必须同时满足资源与依赖的约束: