C++面试与Linux、数据库、算法核心知识点总结
记录第一篇详细阅读的八股文,看看我能回答上来多少
new 和 malloc 的不同
性质和语法不同:一个是C语言 ,一个是C++的运算符
初始化和功能不同:一个只分配内存,不会调用构造函数,所以内存内容是随机的,另一个是会分配内存并且会自动调用对象的构造函数来初始化对象
返回类型:malloc是返回void *,使用时需要强制类型转换,new是返回具体对象类型的指针,类型安全,不需转换。
内存大小:malloc需要程序员手动计算所需字节数并传入,new编译器会自己计算对象的大小
多态重点
多态是面向对象编程(OOP)的重要特性,允许不同的对象对 同一消息(函数调用) 做出不同的响应。在 C++ 中,多态主要通过虚函数来实现。
使用不同的对象对同一消息做出不同的响应。
静态多态:函数重载,主要是在编译时,根据参数列表来确定要调用哪个函数
运行多态:是通过虚函数和继承,在运行时候根据对象的实际调用类型来调用相应的函数
示例:父类指针指向子类对象,调用同名虚函数执行子类版本。
多态函数的底层实现原理:
虚函数表:当类中包含书函数时编译器会生成一个虚函数表,本质是一个函数指针数组,存储了该类所有的虚函数的入口地址
虚函数指针:每个包含虚函数的对象实例中,编译器会隐式插入一个成员变量,即虚函数指针
指针——>指向该函数的虚函数表
调用流程:
当通过调用基类指针或引用调用基函数时
会找到对象的vptr找到对应的vtbl,在表中会查找对应的函数指针,从而看对象实际类型调用函数的效果。
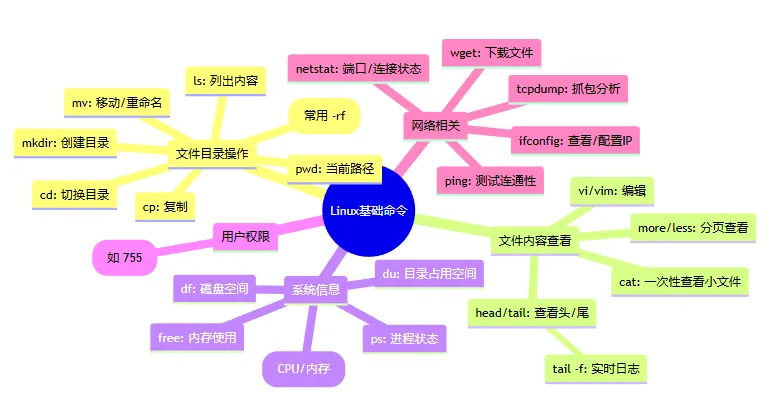
Linux 基础核心
1. 文件和目录操作
- ls:列出目录内容。ls
- cd:切换目录。cd
- pwd:显示当前工作目录路径。pwd
- mkdir:创建新目录。mkdir
- cp:复制文件或目录。cp
- mv:移动或重命名文件。mv
- rm:删除文件或目录(常用
rm -rf强制递归删除)。rm
2. 文件内容查看和编辑
- cat:查看小文件内容(一次性显示)。cat
- more / less:分页查看文件内容(支持翻页)。
- head / tail:查看文件开头/末尾内容(
tail -f常用于实时查看日志)。 - vi / vim:文本编辑器。
3. 系统信息查看
- ps:查看进程状态(常用
ps -ef或ps aux)。ps - top:实时动态查看系统性能和进程(CPU、内存占用)。top
- free:查看内存使用情况。free
- df:查看磁盘空间使用情况。df
- du:查看目录或文件占用的磁盘空间。du
4. 用户和权限管理
- chmod:修改文件或目录的权限(如
chmod 755 filename)。chmod:修改文件或目录的权限
5. 网络相关
- ifconfig:查看或配置网络接口(IP地址等)。ifconfig——查看或配置网络接口
- ping:测试网络连通性。ping——测试网络连通性
- netstat:显示网络状态信息(端口占用、连接状态)。netstat——显示网络状态信息
- tcpdump:抓包工具,分析网络数据包。
- wget:下载文件。
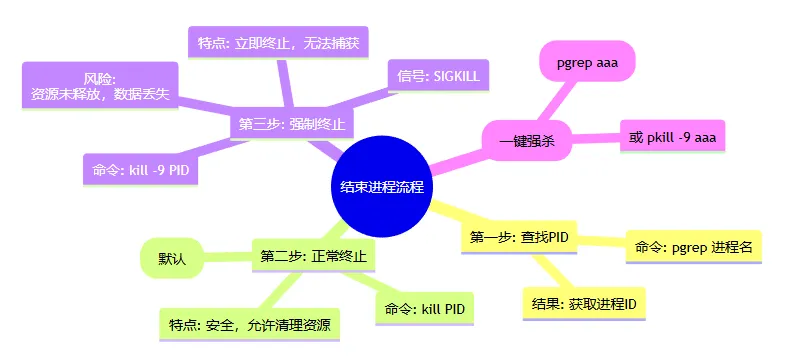
6. 如何结束进程名为 aaa 的进程? (操作流程题)
核心思路:查 PID -> 发信号 -> 强杀
1. 查找进程 PID
使用 pgrep 命令根据名称查找进程 ID。
- 命令:
pgrep aaa - 作用:返回所有名为 “aaa” 的进程的 PID。
2. 正常终止进程
使用 kill 命令发送终止信号。
- 命令:
kill PID(例如:kill 1234) - 原理:默认发送 SIGTERM 信号。
- 特点:请求进程正常退出,进程有机会执行清理工作(如保存数据、释放资源),较为安全。
kill命令向特定的尽成发送信号,发送的SIGTERM信号,进程会正常退出,然后清理进程。
如果没有响应可以用-9进行一个强制的清理,kill -9 可以杀死所有aaa进程
3. 强制终止进程
如果进程无响应,使用 -9 参数强制结束。
- 命令:
kill -9 PID - 原理:发送 SIGKILL 信号。
- 特点:立即终止进程,进程无法捕获该信号,也就无法进行清理工作。
- 风险:可能导致数据丢失或资源未释放,需谨慎使用。
4. 组合命令 (一键操作)
强制结束所有名为 “aaa” 的进程:
kill -9 $(pgrep aaa)(注:也可以使用 pkill -9 aaa 或 killall -9 aaa)
多进程与多线程核心
一、 多进程与多线程的区别
背诵口诀:资源独立与共享、切换开销大与小、稳定性高与低
1. 资源分配方面
多进程:每个进程都有自己的独立空间,通信需要用特殊的IPC机制:管道、消息队列、共享内存,而且安全性高,进程之间是天然隔离的
多线程:共享内存空间,其中的全局变量和堆内存都是共享的,而且通信时比较简单的,可以读取共享变量,但是容易产生资源竞争,需要使用同步机制,比如说互斥锁、信号量
- 多进程:
- 独立地址空间:每个进程拥有独立的内存空间(代码、数据、堆栈)。
- 通信复杂:数据交换需要 IPC 机制(管道、消息队列、共享内存)。
- 安全性高:全局变量互不可见,天然隔离。
- 多线程:
- 共享地址空间:同一进程内的线程共享内存资源(全局变量、堆内存)。
- 通信简单:线程间可直接读写共享变量。
- 同步问题:易产生资源竞争,需使用同步机制(互斥锁、信号量)。
2. 调度与执行开销
从调度和上下文切换来说:
多进程的上下文切换涉及到地址切换和缓存刷新,因此需要保存完整的上下文(寄存器和程序计数器)
多线程由于共享地址空间的原因,切换只需要保存线程的私有数据,比如栈指针,PC和寄存器,不需要保存很多,而且创建和销毁的开销也会小很多
- 多进程:
- 开销大:切换涉及整个地址空间切换、缓存刷新,需保存完整的上下文(寄存器、PC 等)。
- 多线程:
- 开销小:共享地址空间,切换只需保存线程私有数据(栈指针、PC、寄存器)。
- 创建销毁快:比进程快很多,资源开销小。
3. 稳定性与可靠性
稳定性和可靠性来讲:
进程之前相互隔离,一个进程的销毁通常不会影响到其他进程
线程之间共享资源,一个线程出错,比如死锁或者时非法内存访问可能会导致整个进程奔溃
- 多进程:
- 高稳定性:进程间相互隔离。一个进程崩溃(如段错误)通常不会影响其他进程。
- 例子:Web 服务挂了,数据库服务照常运行。
- 多线程:
- 低稳定性:线程共享资源。一个线程出错(非法内存访问、死锁)可能导致整个进程崩溃。
- 例子:多线程服务器中一个线程崩溃,可能导致整个服务瘫痪。
二、 什么情况下使用多进程更好? (场景应用题)
核心场景:隔离需求、多语言集成
如果模块之间独立性要求比较高,不允许单个模块奔溃导致系统整体崩溃,就选择多进程,比如服务气架构中,Web服务进程与数据库进程时相互隔离的,因此一个被攻击导致崩溃的话,那么数据库进程依然会保持安全。
1. 高安全性与稳定性需求
- 场景:系统各模块独立性要求高,不允许单个模块故障导致系统整体崩溃。
- 优势:利用进程隔离性,防止错误扩散。
- 例子:服务器架构中,Web 服务进程与数据库服务进程分离。即使 Web 服务因攻击崩溃,数据库进程依然安全,数据不会受损。
2. 多语言/多模块集成
如果多语言集成的话,不同语言之间由于需要不同的编译环境,内存管理机制也各不相同,因此用进程进行隔离可以避免干扰,同时达成不同语言之间的独立性要求。
- 场景:需要集成不同编程语言编写的模块。
- 优势:不同语言运行时环境、内存管理机制不同,进程隔离可避免冲突。
- 例子:主程序用 C++ 编写高性能计算模块,辅程序用 Python 编写数据分析模块。通过多进程运行,各自独立,互不干扰。
数据库相关
主要使用mysql
一、 基础与存储引擎
1. 常用数据库
- MySQL
2. 常见存储引擎对比
InnoDb:是Mysql的默认引擎,支持ACID的事务级、行级锁、外键约束等等,适用于高并发的读写,数据库完整行性好。
MYISAM:不支持事务,也不支持行级锁,外键,有时是较低的存储空间和内粗宵好,因此适用于大量读的场景。
Memory:数据存储在内存中,速度很快,适用于对性能要求较高的读操作,但是服务气重启或崩溃时候数据会丢失,而且是不支持事务、行级锁和外键约束的。
- InnoDB:MySQL 默认引擎。支持事务、行级锁、外键。适合高并发读写,数据完整性好。
- MyISAM:不支持事务、行级锁、外键。优势是占用空间小,适合大量读操作场景。
- Memory:数据存储在内存中,速度快,但服务重启数据会丢失。不支持事务。
二、 InnoDB 核心特性 (重点)和MYISAM
支持事务、行级锁,锁的粒度小,多个事务可以并发进行,因此并发能力强,MyISAM只能够支持表锁。
而且根据数据库的学习,InnoDb是可以支持日志重做来实现崩溃回复的,这一点保证了数据的持久性和一致性。
背诵口诀:事务、行锁、崩溃恢复
- 事务支持:提供 ACID(原子性、一致性、隔离性、持久性)支持,MyISAM 不支持。
- 并发性能:采用行级锁,锁粒度小,并发能力强;MyISAM 仅支持表锁。
- 崩溃恢复:通过 Redo Log(重做日志)实现崩溃恢复,保证数据持久性和一致性。
三、 InnoDB 与 MyISAM 深度区别 (高频考点)
背诵口诀:事务、索引、锁、计数
事务支持
InnoDB:支持事务。
MyISAM:不支持事务。
这是十分重要的一点,导致InnoDb成为默认引擎的重要一环
索引结构
聚簇索引是数据文件和主键索引进行绑定,叶子节点存数据,主键查询非常高,因此必须有主键。
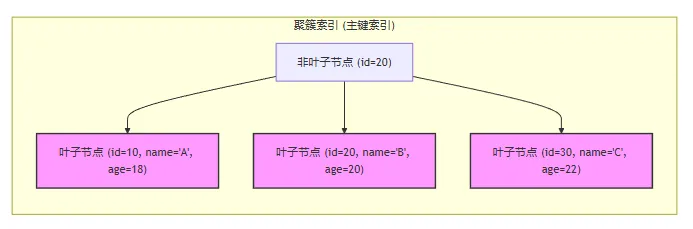
image-20260309230206662 叶子节点直接就是存储整行的数据,数据是有序的,直接按照进行顺序物理存储,数据紧紧挨着索引。
非聚簇索引:索引文件和数据文件是分离的,B+树的叶子节点存访的是指向数据物理地址的指针,叶子节点上存储了数据在磁盘上的地址,数据文件是独立存在的,不随索引的顺序而排列,通常按插入顺序排放。
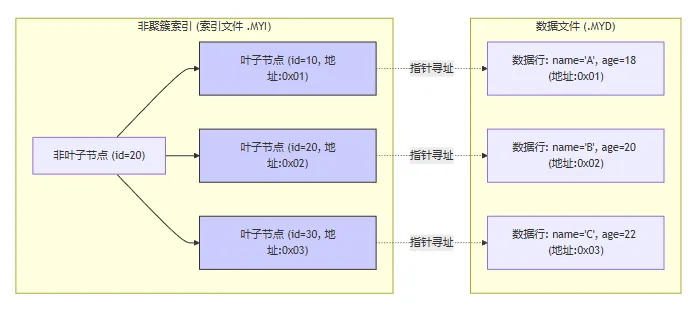
image-20260309230217572 聚簇索引是一张表只能有一个的,因为数据行只能按照一种顺序物理存放,在InnoDb中,主索引是数据文件,如果没有定义主键的话,Mysql会自动选择一个唯一的非空索引代替,若也没有,则生成一个隐藏的6字节RowID代替。
非聚簇索引可以有多个,主键索引和辅助索引一致。
索引-》地址-》数据
如果数据行发生移动,非聚簇索引可能需要修改所有指向该行的指针(因为数据原先存放在那个地址上,然后移动开了,所以会导致地址需要发生变动),而聚簇索引只需要修改主键索引,因为辅助索引存储的是主键值。
- 访问方式(回表):辅助索引 -> 主键 ID -> 主键索引树 -> 数据。
场景 聚簇索引 非聚簇索引 主键查询 极快。直接从 B+ 树根节点遍历到叶子节点即拿到数据,一次 I/O 即可。 较慢。先查索引树拿到地址,再根据地址去数据文件读取数据(通常涉及两次 I/O 或随机 I/O)。 辅助索引查询 需要“回表”。先查辅助索引树拿到主键 ID,再查聚簇索引树拿到数据。过程较长。 无需“回表”。直接查索引树拿到地址,然后去数据文件读取。主键和辅助索引查询流程一致。 范围查询/排序 高效。因为数据物理上按主键顺序存放,利于顺序 I/O 读取。 低效。数据是随机存放的,范围查询会产生大量的随机 I/O(磁头频繁移动)。 详细解释一下回表机制:如果是InnoDB是需要那道辅助索引去找到主键ID,然后再根据主键ID去找到叶子节点,会需要访问两次
如果是MYISAM的话,只需要找到Alice然后拿到地址就OK了。
SELECT * FROM User WHERE name = 'Alice';(假设name上有索引)InnoDB 流程(回表):
- 在
name的辅助索引 B+ 树中,找到Alice。 - 拿到
Alice对应的主键 ID(例如id=10)。 - 拿着
id=10去主键索引(聚簇索引)的 B+ 树中查找。 - 在主键索引的叶子节点找到
id=10的完整数据行。
MyISAM 流程:
在
name的索引 B+ 树中,找到Alice。直接拿到数据文件的物理地址(例如
0x01)。去
.MYD文件的0x01位置读取数据。
总结:InnoDB 的辅助索引查询比主键查询慢,因为多了一次遍历 B+ 树的过程。这也就是为什么我们常说“尽量使用主键查询”的原因。
- InnoDB:聚簇索引。数据文件与主键索引绑定在一起(叶子节点存数据)。
- 特点:必须有主键,主键查询效率极高;辅助索引需“回表”(先查主键再查数据)。
- MyISAM:非聚簇索引。数据文件与索引文件分离(叶子节点存数据指针)。
- 特点:主键索引与辅助索引结构独立,访问方式一致。
锁粒度
这是一个锁粒度的问题,关乎于并发
- InnoDB:支持行级锁。更新时只锁一行,并发高。
- MyISAM:只支持表级锁。更新操作会锁整张表,阻塞其他读写。
Count 效率
这个点很熟悉,因为InnoDB它没有保存行数,另一个会保存一个内不变量保存了行数
- InnoDB:不保存行数,
count(*)需全表扫描,效率低。 - MyISAM:内部变量保存行数,
count(*)直接读取,效率极高。
- InnoDB:不保存行数,
四、 MySQL 索引数据结构:B+ 树 (底层原理)
非叶子节点是存储索引不存储数据,叶子节点会存储数据/数据指针,而且所有的叶子节点是通过双向链表进行连接的,因此很适合进行范围查询。
1. B+ 树结构特点
- 非叶子节点:只存储索引值,不存数据(能容纳更多索引,降低树高度)。
- 叶子节点:存储数据/数据指针,且所有叶子节点通过双向链表连接(适合范围查询)。
- 层级:通常 3-4 层即可存储千万级数据。
2. 查询过程 (以主键查询为例)
假设查询 id = 5 的数据,过程如下:
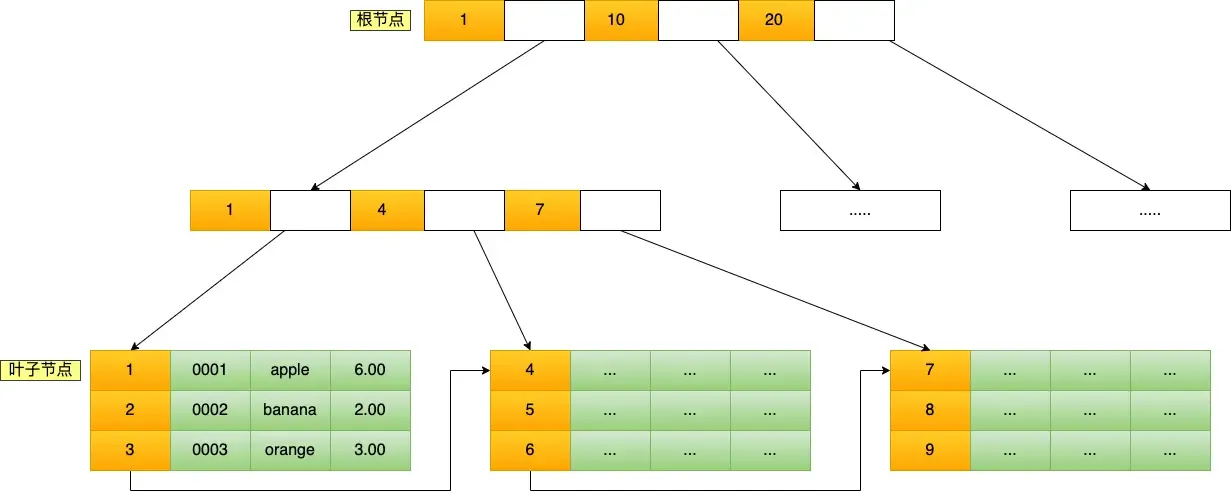
- 根节点:加载磁盘块 1,找到索引 (1, 10, 20)。5 在区间 [1, 10),指向下一层。
- 中间节点:加载对应磁盘块,找到索引 (1, 4, 7)。5 在区间 [4, 7),指向下一层。
- 叶子节点:加载对应磁盘块,找到索引数据 (4, 5, 6),定位到
id=5的行数据。
3. 性能优势
- IO 次数少:树高度低(3-4层),意味着查询一次数据只需 3-4 次磁盘 I/O。
- 范围查询快:叶子节点形成链表,适合执行
where id > 5这类范围查询。
查找数据非常块,存储千万级别的数据,查询效率非常高,即便数据量很大,查询一个数据的磁盘IO也只需要3-4次。
算法
一、 字符串相加
1. 题目描述
给定两个以字符串形式表示的非负整数 num1 和 num1,返回它们的和(同样以字符串形式表示)。 注意:不能直接将字符串转换为整数,因为数值可能非常大。
2. 解题思路 (竖式加法模拟)
核心逻辑:模拟人工手算加法的过程(竖式加法)。
- 对齐:使用双指针,分别指向两个字符串的末尾(即最低位)。
- 逐位相加:从低位向高位遍历,逐位相加,并加上上一轮的进位。
- 处理进位:计算当前位的和
sum,当前位结果为sum % 10,新的进位为sum / 10。 - 结果拼接:将计算结果字符拼接到结果字符串中。
- 结束处理:遍历结束后,如果进位不为 0,需要额外补一位。
3. 代码实现
string addstring(string nums1,string nums2)
{
int i=nums1.length();
int j=num2.length();
int carry=0;
string res="";
while(i>=0||j>=0||carry!=0)
{
int x=(i>=0)?nums[i]-'0':0;
int y=(j>=0)?nums[j]-'0':0;
int sum=x+y+carry;
res.push_back('0'+sum%10);
carry=sum/10;
i--;
j--;
}
reverse(res.begin(),res.end());
return res;
}二、 二进制中 1 的个数
1. 题目描述
输入一个整数(可以是负数),输出该数二进制表示中 1 的个数。 注:负数在计算机中以补码形式存储。
2. 解题思路 (位运算技巧)
常规思路:循环检查每一位是否为 1。
- 问题:对于 C++ 中的负数,右移操作(
>>)通常进行的是算术右移(高位补 1),会导致死循环。
优化思路 (n & (n - 1)):利用位运算的性质。
- 核心公式:
n = n & (n - 1) - 原理:这个操作会将整数
n的二进制表示中,最右边的那个1变成0。 - 步骤:循环执行该操作,直到
n变为 0。循环的次数就是二进制中1的个数。 - 优势:避免了负数右移的死循环问题,且效率更高(有多少个 1 就循环多少次)。
直接使用n=n&n-1来进行实现,直到n变成0
3. 代码实现
int hammingWeight(uint32_t n) {
int count = 0;
while (n != 0) {
// 每次消去最右边的1
n = n & (n - 1);
count++;
}
return count;
}
// 如果题目输入是 int 类型,核心逻辑一致:
int NumberOf1(int n) {
int count = 0;
// 注意:如果是直接操作 int n,C++ 中 n & (n-1) 操作是合法的
// 因为这会自动处理补码形式
while (n != 0) {
n = n & (n - 1);
count++;
}
return count;
}